Building Specialized Chat Assistants with AWS and OpenAI
Introduction
In recent years, there has been a growing interest in building specialized chat assistants to cater to various domains and industries. These chatbots provide tailored assistance to users by leveraging the power of large language models (LLMs) and embeddings. In this article, we will explore the process of creating a specialized chat assistant, such as an AWS Amplify chatbot, capable of understanding the latest Amplify documentation and providing relevant information beyond the knowledge scope of a base ChatGPT. We will also discuss how this approach can be applied to various content types, making them easily searchable and accessible through a chatbot interface.
Understanding Large Language Models (LLMs) and Embeddings
A large language model (LLM) is a type of language model that comprises a neural network with billions of weights or more, trained on vast amounts of unlabelled text data using self-supervised learning techniques. LLMs are transformer-based neural networks that utilize deep learning for natural language processing (NLP) and natural language generation (NLG) tasks. The model's primary goal is to predict the next text that is likely to come next, and its sophistication and performance can be judged by the number of parameters it has.
Embeddings are dense numerical representations of real-world objects and relationships, expressed as a vector. The vector space quantifies the semantic similarity between categories. Embedding vectors that are close to each other are considered similar. Embeddings can be used directly for applications like recommending similar items in e-commerce stores or passed to other models to share learnings across similar items, unlike one-hot encodings that treat them as completely unique categories.
Building a Specialized Chat Assistant System
A specialized chat assistant system can be built using a few modules, such as an API server, search service, database, and OpenAI API. The system generally follows two main flows that utilize embeddings as a memory bank for a LLM:
- Generate the embeddings from a body of data. This involves removing irrelevant or redundant information. Converting the data into a suitable format. And adding bias or metadata to the embedding.
- To answer user queries, first, look up relevant data based on embeddings similarity, then add the extra data to the chat context. This also involves fetching the associated text or information from the database such as links to source documents.
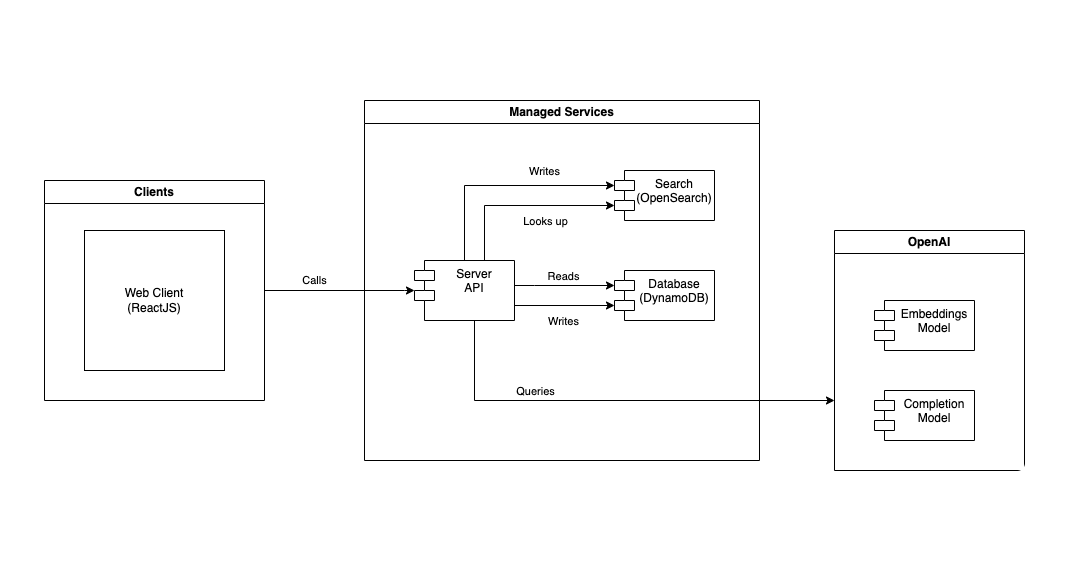
In the first flow, the API server generates the embeddings using the OpenAI API and stores the vectors in an OpenSearch instance. In the second flow, the server looks up embeddings for a user query based on cosine similarity. The server then creates a meta prompt that includes the looked-up text from embeddings and the original user query. Finally, the server uses the OpenAI API to generate text completion, which should answer the user's original query.
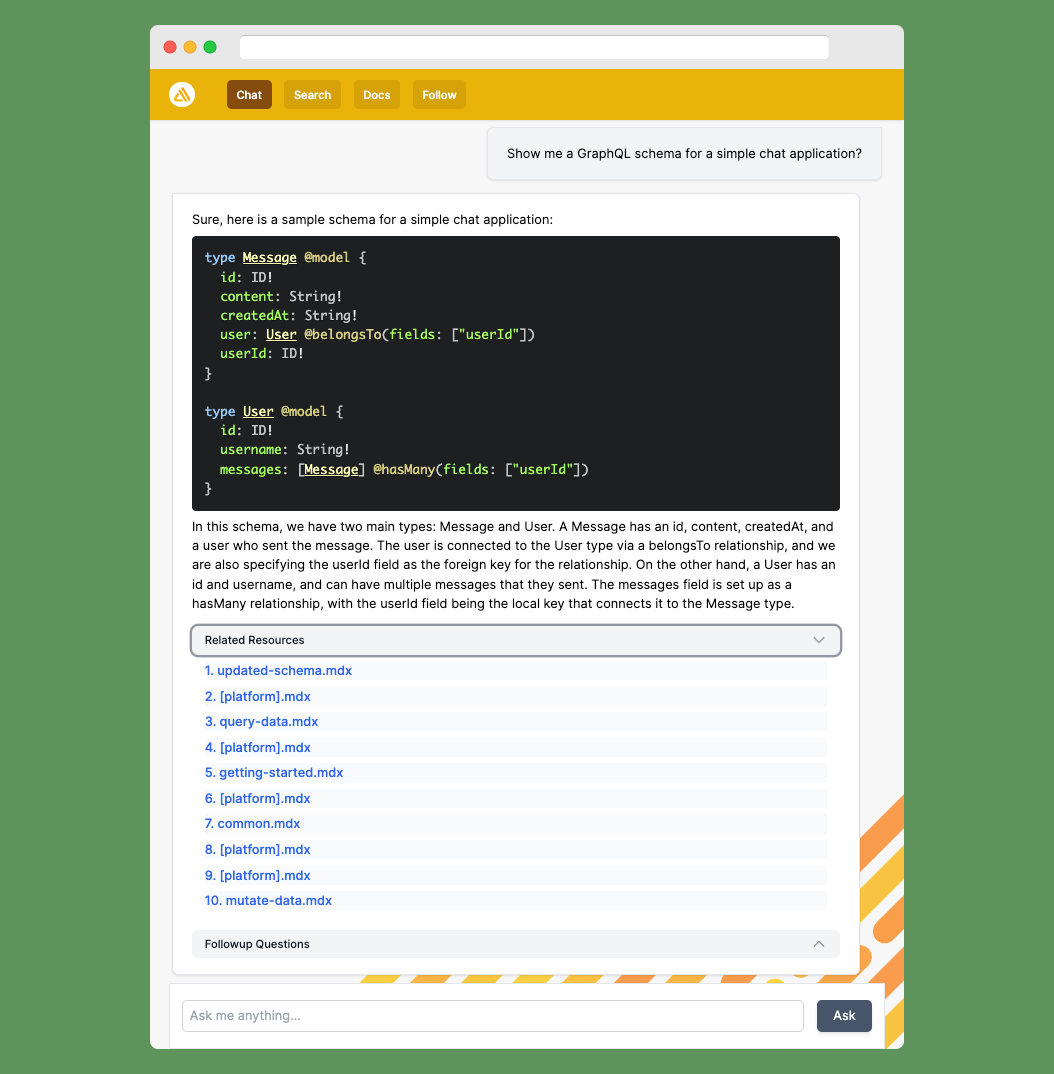
For the AWS Amplify chatbot, we create embeddings from the documentation available on GitHub. Although these are markdown files and not an ideal source, they work reasonably well most of the time. When a user asks a question in the chat, we use a system prompt that guides the AI to act like a pair programmer working with AWS Amplify, focusing on code and providing concise responses.
Expanding the Approach to Various Content Types
The versatile methodology of generating embeddings from a body of text and employing semantic similarity lookup to enhance a large language model's specialized knowledge can be applied to a diverse range of content types. This approach empowers chatbots to search and consume various forms of content, including emails, podcast transcriptions, files, financial reports, technical documentation, medical journals, and numerous other use cases. By adapting this technique, organizations across industries can develop highly customized chat assistants that cater to their unique needs and deliver pertinent, tailored information to users.